
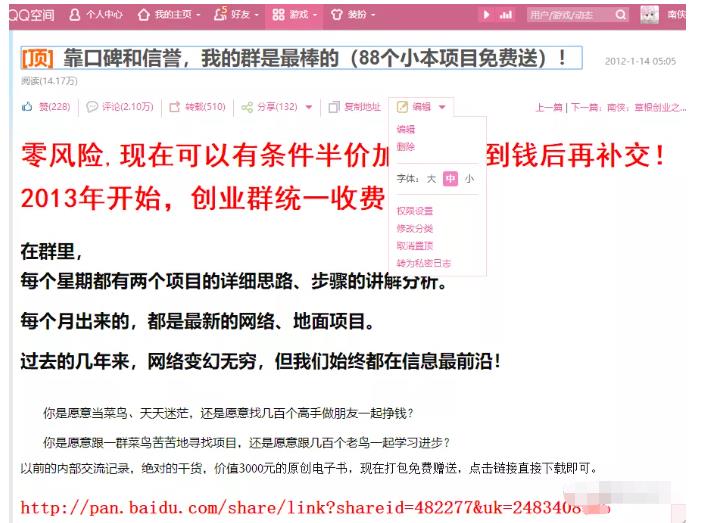
纯草根的我,QQ空间写的一篇四千多字的日志,几年前就带来一千多付费群友,直接变现了100万以上(文章还在,但社群已死,因此所有联系方式都特地打了马赛克,这里只作为案例为大家详细拆
感兴趣的可以下载学习
声明:
本站资源来自会员发布以及互联网公开收集,如遇充值环节或绑定支付账户等异常步骤,建议停止操作,是否有风险请自行甄别,本站概不负责。
本站资源仅做学习和交流使用,版权归原作者所有,发布的内容若侵犯到您的权益,请联系站长删除,微信:hanshe120

有效期:购买后永久有效
最近更新:2021年11月03日
纯草根的我,QQ空间写的一篇四千多字的日志,几年前就带来一千多付费群友,直接变现了100万以上(文章还在,但社群已死,因此所有联系方式都特地打了马赛克,这里只作为案例为大家详细拆
感兴趣的可以下载学习
本站资源来自会员发布以及互联网公开收集,如遇充值环节或绑定支付账户等异常步骤,建议停止操作,是否有风险请自行甄别,本站概不负责。
本站资源仅做学习和交流使用,版权归原作者所有,发布的内容若侵犯到您的权益,请联系站长删除,微信:hanshe120



